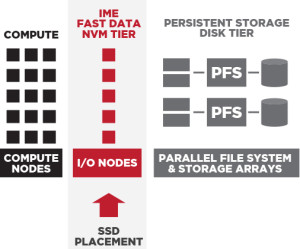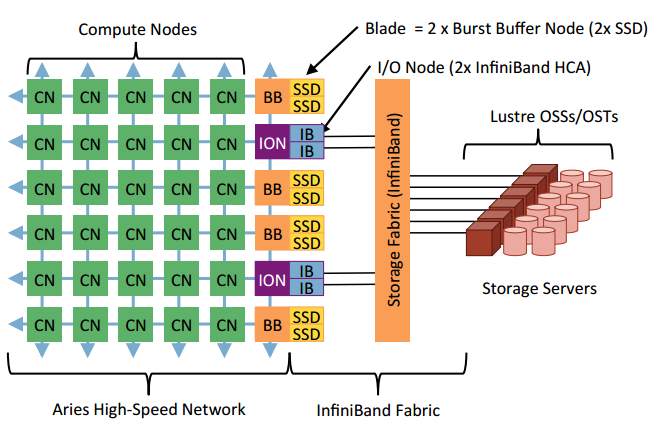
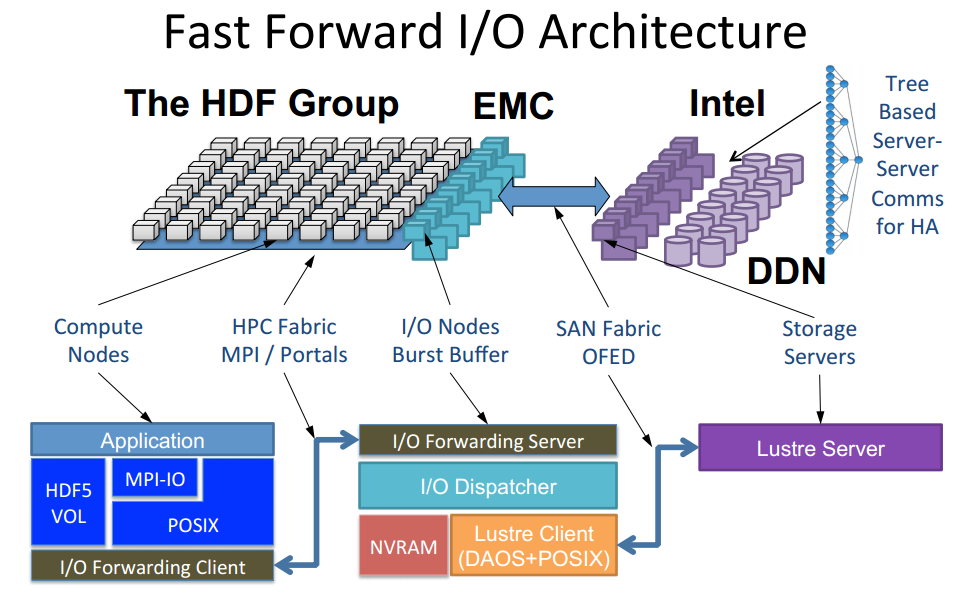
The purpose of burst buffers is to absorb bulk data produced by applications a hundred times faster than what the parallel file system can absorb while draining the data to the PFS on the back end. Burst buffers sit between the HPC application and the parallel file system as an intermediate high speed layer of storage.
A burst buffer consists of a combination of rapidly accessed persistent memory with its own processing power. The persistent memory is positioned between a set of processors with their non-persistent memory counterparts and a chunk of symmetric multi-processor compute through direct PCIe high bandwidth links. The back end of the burst buffer is comprised of slower large capacity storage systems.
In other words: Would you like to add a hyper-fast storage tier between the compute nodes and your parallel file system? Then you have come to the right place.
A little more detail on the specifics. The burst buffer’s purpose is to allow applications running on an SMP’s fast processor cores to perceive that the application data – data first residing in the SMP’s local and volatile memory – will be quickly saved on some persistent media. As far as the application is concerned, its data, once written into the burst buffer, had become persistent with a very low latency; the application did not need to wait long to learn that its data had been saved. If the power goes off after the completion of such a write, the data is assumed to be available for subsequent use.
Where would I use a Burst Buffer?
- Periodic bursts – use to flatten the latency curve and reduce IO spikes causing latency.
- Staging-in – Data that is utilized multiple times of large files can be staged in at the beginning of a job to maximize performance.
- Staging-in –application data can be staged at the beginning of a job to maximize performance.
- I/O improvements – to provide better IO for high IO applications.
Who is developing a Burst Buffer?
Within the HPC community, several vendors have released and are continuing to develop burst buffers including DDN, EMC and NetApp. The diagram below represents NERSC’s approach to creating a burst buffer architecture out of Cray DataWarp appliances. In total 1.5PB of burst buffer will front end over 100PB of capacity. The following is a conceptual diagram depicting the deployment.
The challenge in using the burst buffer at a smaller scale, say a DDN IME device front-ending GPFS-based GridScaler or a Lustre-based ExaScaler is to identify workloads and integrate scripts to take advantage of the buffer space that make sense.